Table of content
Deduplication involves the identification and removal of duplicate or redundant data within a dataset. This practice is especially valuable in scenarios where data replication occurs, such as during backups, file storage, or within databases.
The process of deduplication is executed through a variety of techniques. One common approach involves breaking data into smaller chunks or blocks and then comparing these chunks. When duplicate chunks are identified, the system retains only a single instance while referencing it for subsequent occurrences. This method is particularly efficient for minimizing storage requirements, making data backups faster and more efficient, and enhancing data transfer speeds.
What are the different types of deduplication
Data deduplication tools are commonly sorted into three distinct methods.
On-demand deduplication
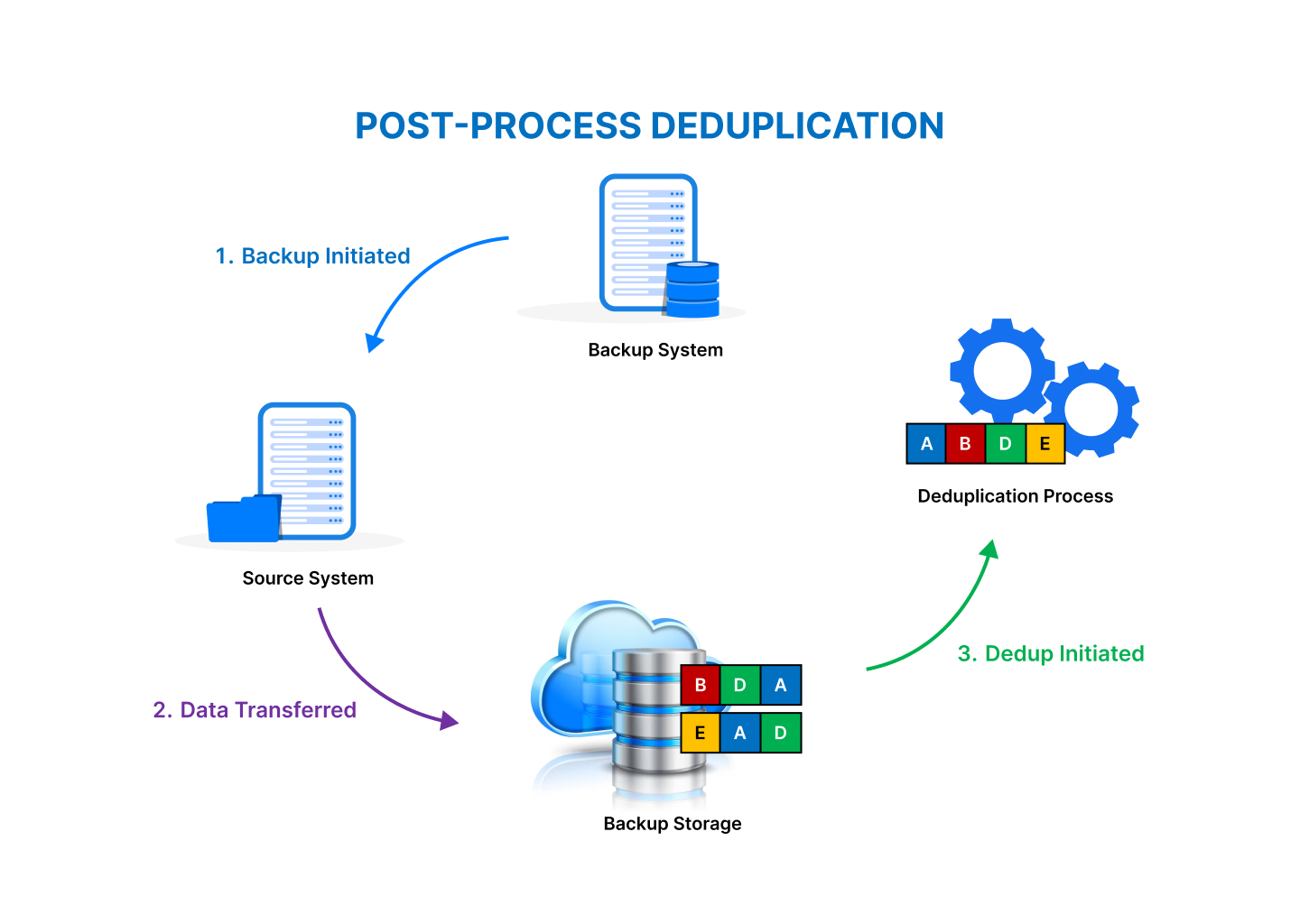
In this deduplication approach, known as post-processing, an individual triggers the data deduplication software to identify and merge redundant data intentionally.On-demand deduplication works by comparing each new block of data to the existing data blocks on the storage system. If a duplicate block is found, the new block is not stored, and a reference to the existing block is used instead. This process is typically performed in the background, so it does not impact the performance of the storage system.
Benefits of On-Demand Deduplication
On-demand deduplication offers a number of benefits, including:
- Reduced storage costs:By eliminating duplicate data blocks, on-demand deduplication can significantly reduce the amount of storage space required.
- Improved performance:On-demand deduplication can improve the performance of storage systems by reducing the amount of data that needs to be read and written.
- Increased data protection:On-demand deduplication can help to improve data protection by reducing the risk of data loss. If a duplicate data block is lost or corrupted, the other copy of the block can still be accessed.
Automated deduplication
In this method, an automated data deduplication system is triggered and disabled based on rules and schedules defined by the user.The automated data deduplication solution is set to activate based on the rules established by the user. When new data is introduced into the system, the solution continuously monitors it for potential duplicates.
Preventative deduplication
In this method, the Dedupe tool is designed to prevent duplication functions within sales and marketing platforms. Its purpose is to intercept redundant data originating from forms, integrations, and imports, thus ensuring that it never reaches the storage system.
Types of Data Deduplication
Inline vs. Post-Process Deduplication
Inline deduplication processes data as it is written, ensuring that only unique data is stored. Post-process deduplication, on the other hand, scans the data after it's written, identifying duplicates at a later stage.
Source-Based vs. Target-Based Deduplication
Source-based deduplication occurs at the data source before it is transmitted to the target system. Target-based deduplication, as the name suggests, performs deduplication at the destination.
Chunk-Level vs. File-Level Deduplication
Chunk-level deduplication breaks data into smaller segments, analyzing and eliminating duplicates at the chunk level. File-level deduplication, on the other hand, focuses on entire files.
Matching techniques used in deduplication
Exact Matching
Exact matching is a data deduplication technique that identifies and eliminates duplicate records by comparing data fields for an exact match. This method is particularly useful when you want to ensure that records are identical in specific data attributes
Fuzzy Matching
Fuzzy matching is a refined data deduplication technique that goes beyond exact matches to identify records with similar but not necessarily identical values. It is particularly useful when dealing with data that may have variations, misspellings, or typographical errors.
Hash-Based Matching
The first step in hash-based deduplication is to break data into smaller "chunks." These chunks can be of fixed or variable length, and they represent portions of the data.
Each chunk of data is processed using a hashing algorithm. Commonly used algorithms include SHA-1 and MD5, among others. The hashing algorithm computes a fixed-length hash value (a string of characters) based on the content of the chunk.
The resulting hash values serve as unique identifiers for each chunk of data. Identical chunks will produce the same hash value, allowing for easy comparison.
Delta Differencing
Delta differencing is a technique used in data deduplication , particularly in storage and backup systems. This method focuses on identifying and storing only the differences (delta) between versions of data, rather than duplicating entire files or datasets.
Content-Based Matching
Content-Based Matching is a deduplication technique that involves comparing the actual content of data records to identify duplicates. This approach is particularly useful when dealing with unstructured or semi-structured data where records may not have strict formatting or common identifiers.
Pattern Matching
Pattern matching is a technique used in deduplication to identify and eliminate duplicate records based on predefined patterns or templates. This method involves comparing data records with known patterns to determine whether they match, indicating the presence of duplicates.
Get StartedData Deduplication vs. Data Compression
Data deduplication is focused on removing duplicate data blocks to save storage space while maintaining data integrity. Data compression, on the other hand, aims to represent data more efficiently using algorithms, potentially leading to variable levels of data loss. The choice between deduplication and compression depends on the specific use case and the trade-off between data preservation and storage efficiency.

Working of Deduplication
Data deduplication is the process of identifying and eliminating duplicate data in storage systems. It operates at two levels: file-level and sub-file level. In some systems, only complete files are compared, known as Single Instance Storage (SIS), which can be less efficient when minor modifications require re-storing entire files.
- Block Division:Data blocks are divided into smaller sub-blocks. Each sub-block is assigned a unique identification key (index) generated using a cryptographic hash function.
- Duplicate Detection:The system compares these index keys, looking for identical hash keys. If two identical hash keys are found, it suggests that the related data blocks are likely identical. An additional check can be performed to confirm their identical nature.
- Replacement or Storage:If a block of data already exists in the deduplication repository, it's replaced with a Virtual Index Pointer, linking the new sub-block to the existing block of data. If the sub-block is unique, it's stored in the deduplication repository, and a virtual index is created in memory for efficient comparison with new data reads.
This approach optimizes storage space and minimizes data redundancy by efficiently identifying and managing duplicate data at a granular level, improving storage efficiency and reducing data storage costs.
Factors Influencing Data Deduplication Efficiency
- Data Type: The type of data being deduplicated plays a significant role. Some data types are more amenable to deduplication than others. For example, redundant data in text files may be easier to identify compared to multimedia files.
- Data Variability Rate: The rate at which data changes or varies impacts deduplication. Data that changes frequently might have lower deduplication ratios as there are fewer opportunities to identify duplicates.
- Data Size and Volume:The size and volume of data to be deduplicated affect efficiency. Large data sets provide more opportunities for finding duplicate data, potentially leading to higher deduplication ratios.
- Deduplication Method:The method used, such as inline or post-process deduplication, can influence efficiency. Inline deduplication occurs as data is ingested, while post-process deduplication happens after data is stored. The choice of method depends on the specific use case
Generative AI models can parse resumes more accurately and efficiently than traditional methods. Generative AI models are trained on a large dataset of resumes, which allows them to learn the tone of human language and identify relevant information even when it is presented in a variety of formats. Additionally, generative AI models can parse resumes much faster than traditional methods, as they can process multiple resumes in parallel.
How to ensure data security during data deduplication?
- Encryption: Encrypting data before deduplication is crucial to protect sensitive information. Encryption ensures that even if duplicate data is stored, it remains secure and unreadable to unauthorized users.
- Access Controls:Implement stringent access controls and authentication mechanisms to restrict access to deduplicated data. Only authorized personnel should have the privilege to manage and retrieve data.
- Data Classification: Prioritize data classification to identify the sensitivity of data. Not all data requires the same level of security. Classify data and apply security measures accordingly.
- Regular Auditing:Conduct regular audits and monitoring of data deduplication systems to detect any unauthorized access or suspicious activities. This helps in identifying and responding to security breaches promptly.
- Secure Key Management: Properly manage encryption keys. A robust key management system ensures that encryption keys are protected and accessible only to authorized personnel.
- Testing and Validation: Thoroughly test and validate the deduplication system to ensure that it doesn't introduce vulnerabilities or data leakage
- Secure Deduplication Algorithms: Implement secure deduplication algorithms that are designed with security in mind. Some deduplication methods, such as convergent encryption, offer additional security layers.Data Integrity: While deduplication is primarily for storage optimization, organizations should always prioritize data integrity. Ensure that data remains intact and unaltered throughout the deduplication process.
- Disaster Recovery: Have a robust disaster recovery plan in place to recover data in case of unexpected incidents, ensuring business continuity
- Employee Training:Train employees and staff on data security best practices and the importance of safeguarding data during deduplication processes.
What are the benefits of deduplication?
- Reduced Storage Costs: By eliminating redundant data, deduplication significantly reduces the amount of storage space needed. This leads to cost savings in storage infrastructure.
- Improved Data Management:Deduplication simplifies data management by ensuring that only unique data is stored. This makes data retrieval and backup processes more efficient
- Resource Optimization:Businesses can make better use of their resources when they don't have to store multiple copies of the same data. This can lead to improved overall efficiency.
- Enhanced Data Retention:Deduplication allows for larger backup capacity and longer-term data retention. It also ensures continuous verification of backup data, improving data reliability.
- Cloud Efficiency:Data deduplication is particularly beneficial for organizations that work with highly redundant operations and need to copy and store data in the cloud. It reduces data transfer and storage costs in cloud environments.
- Data Accuracy:With deduplication, you reduce the risk of errors caused by having multiple copies of the same data. This can improve data accuracy and consistency.
Use Cases
Data Backup and Storage
Data deduplication is widely used in backup solutions to reduce the amount of data that needs to be stored and transferred, thereby saving storage space and time.
Virtualization and Data Centers
In virtualized environments and data centers, deduplication plays a crucial role in optimizing storage, improving performance, and simplifying data management.
Cloud Computing
Cloud providers use data deduplication to efficiently store and manage vast amounts of customer data, ensuring cost-effective services.
Database Management
Databases often contain redundant data. Deduplication helps in maintaining data integrity, improving query performance, and reducing database size.
Conclusion
Data deduplication is a valuable tool that can help organizations of all sizes save money, improve data quality, and enhance security. It is a powerful way to reduce the amount of storage space required for data, which can lead to significant savings on storage costs.
In addition to saving money, data deduplication can also improve data quality by identifying and removing duplicate data from a dataset. This can make it easier to find the information you need and can help to improve the accuracy of analysis.
Finally, deduplication can also enhance security by reducing the attack surface. Duplicate data can be exploited by attackers to gain access to sensitive information or launch denial-of-service attacks. By removing duplicate data, organizations can make it more difficult for attackers to succeed.
Overall, deduplication is a valuable tool that can help organizations of all sizes save money, improve data quality, and enhance security. It is a technology that is becoming increasingly important as the volume of data continues to grow.