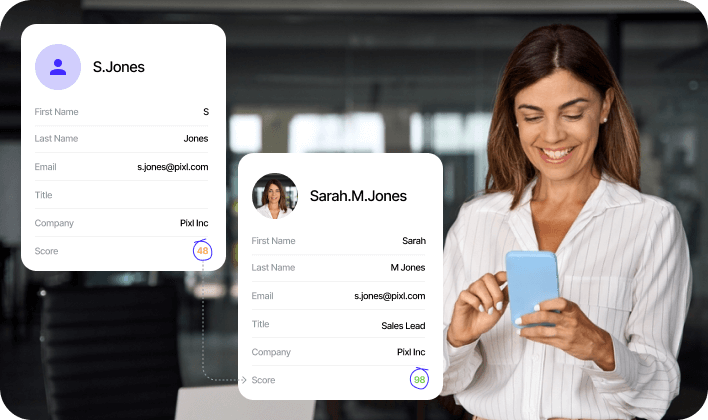
What is Dedupe?
Dedupe, also known as Data deduplication, is the practice of eliminating repetitive information from databases and lists, ensuring that each entity or record is unique. This process may encompass merging or eliminating surplus records and confirming the accuracy of data in every field of the record.
Data Deduplication Tools are Commonly
Classified into Three Distinct Methods
On-demand deduplication
This method of deduplication involves post-processing, where an individual initiates the data deduplication software to identify and combine redundant data.
Automated deduplication
In this approach, an automated data deduplication solution activates and deactivates according to user-defined rules and schedules.
Preventative deduplication
Duplication-preventing software blocks redundant data in sales and marketing platforms, stopping duplicates from forms, integrations and imports before storage.
01
Upload It

You can either upload a spreadsheet file or establish a direct connection to the database.
02
Train It

We offer training on how to effectively identify akin or comparable records within your dataset.
03
Validate It

Matches are automatically identified for your review.
Different Dedupe Approaches
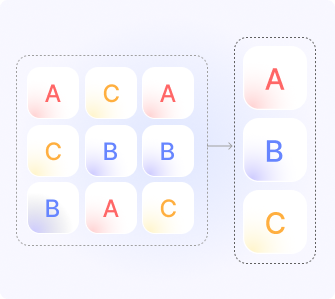
Exact Matching
Identifies and removes identical copies of data.
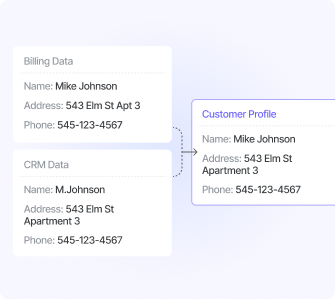
Fuzzy Matching
Identifies and removes identical copies of data.
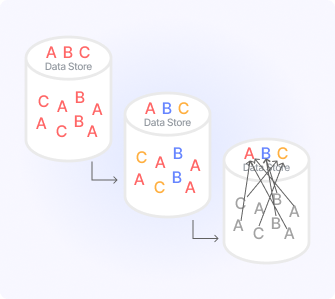
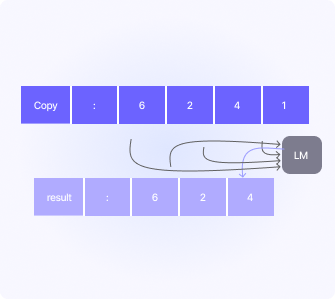
Hash-Based Matching
Assigns unique identifiers (hashes) to data chunks for comparison.
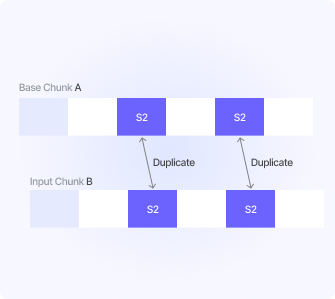
Delta Differencing
Compares data chunks and stores only the differences.
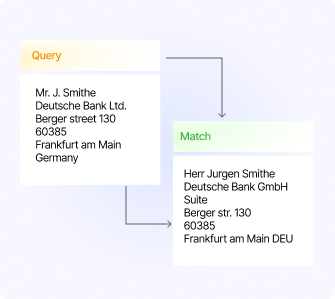
Content-Based Matching
Analyzes the content of data to identify duplicates.
Pattern Matching
Uses predefined patterns or regular expressions to detect duplicates.
-

Improved data
qualityDeduplication software can help to improve the quality of data by removing duplicate data. This can lead to more accurate insights, better decision-making and improved business performance.
-

Improved compliance
Deduplication software can help you to comply with data protection regulations by ensuring that your data is accurate and up-to-date. This can help to reduce the risk of data breaches and fines.
-

Implement custom
merge behaviorEliminate uncertainty in data deduplication by customizing merge and survivorship rules to align with your specific requirements.
-

Reduced bandwidth usage
Deduplication software can help to reduce bandwidth usage by reducing the amount of data that needs to be transferred over the network. This can be especially beneficial for businesses that need to transfer large amounts of data between different locations.
-

Cloud Efficiency
Data deduplication is particularly beneficial for organizations that work with highly redundant operations and need to copy and store data in the cloud. It reduces data transfer and storage costs in cloud environments.
Defining
Characteristics of Deduplication

Advanced techniques
for matching fields and
records.
Determine duplicate
clusters within or
between datasets
Combine and update
records to safeguard
against data loss
Configurable criteria for
identifying the master
record
FAQS
Frequently Asked Questions
Data deduplication works by identifying and removing duplicate data, using techniques like hash-based and delta differencing.
Benefits include reduced storage costs, faster backups and enhanced data transfer efficiency.
Data deduplication is effective in data backup, virtualization and email archiving.
Data deduplication removes duplicate data, while data compression reduces file size; use them together for optimal results.
Encrypt deduplicated data and ensure compliance with security regulations.
Efficiency depends on data type and deduplication method; measure effectiveness using deduplication ratio.
Future trends include AI-enhanced deduplication and hybrid deduplication solutions.
Calculate ROI by analyzing cost savings and long-term benefits from reduced storage requirements.